Scraping Music: Difference between revisions
No edit summary |
(Updated for v18) |
||
| Line 4: | Line 4: | ||
= Introduction = | = Introduction = | ||
<section begin="intro"/>Music Scraping downloads additional information about the Artists and Albums in your library, as well as downloading any missing artwork | <section begin="intro"/>Music Scraping downloads additional information about the Artists and Albums in your library, as well as downloading any missing artwork. This step is optional, but if you choose to scrape, it must be performed after your music is Scanned into the library.<section end="intro"/> | ||
The source of information for the scrape can be either: | |||
#An online source using one of the Kodi Scrapers | |||
''' | #Local information from either '''''[[NFO files]]''''' or data in a '''''[[Import-export_library/Music|Single File]]''''' export. | ||
For this guide, it is assumed this is your first setup, so you will have no local files. The scraped data is being retrieved from an online source using the scrapers. | |||
v18 introduces a number of changes and improvements to scraping. The most prominent being the [[Artist information folder]]. Also new is the ability for {{kodi}} and the scrapers to download and cache Extended Artwork. These are covered below. | |||
= What is Scraped = | = What is Scraped = | ||
If the information and artwork is available at the online site used by the active scrapers, the scraping process will download the additional data and artwork into your existing library. | |||
== Artists == | == Artists == | ||
The below table details the '''additional''' information {{kodi}} scrapes into the library. This data cannot be scanned from tags | The below table details the '''additional''' information {{kodi}} scrapes into the library. This data cannot be scanned from tags. | ||
{|class="prettytable" | {|class="prettytable" | ||
|- | |- | ||
! colspan="8" style=" background-color:#12b2e7; text-align:left;" | '''Artist Metadata''' | |||
|- | |- | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | biography | ||
| style=" width: | | style=" width:200px; text-align:left;" | birthday date and place | ||
| style=" width:200px; text-align:left;" | | | style=" width:200px; text-align:left;" | date and place died | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | disambiuation | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | discography | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | gender | ||
| style=" width:150px; text-align:left;" | genres | |||
| style=" width:150px; text-align:left;" | instruments | |||
|- | |||
| style=" width:200px; text-align:left;" | mbid's | |||
| style=" width:150px; text-align:left;" | moods | |||
| style=" width:150px; text-align:left;" | SortName | |||
| style=" width:150px; text-align:left;" | type | |||
| style=" width:200px; text-align:left;" | styles | |||
| style=" width:150px; text-align:left;" | years active | |||
| style=" width:150px; text-align:left;" | (band) formed | |||
| style=" width:150px; text-align:left;" | (band) disbanded | |||
|- | |||
! colspan="8" style=" background-color:#12b2e7; text-align:left;" | '''Artist Artwork''' | |||
|- | |||
| style=" width:150px; text-align:left;" | banner | |||
| style=" width:200px; text-align:left;" | clearart | |||
| style=" width:200px; text-align:left;" | clearlogo | |||
| style=" width:150px; text-align:left;" | fanart | |||
| style=" width:150px; text-align:left;" | fanart# (extrafanart) | |||
| style=" width:150px; text-align:left;" | folder (thumb) | |||
| style=" width:150px; text-align:left;" | landscape | |||
|} | |} | ||
| Line 58: | Line 58: | ||
== Albums == | == Albums == | ||
The below table details the '''additional''' information {{kodi}} scrapes into the library. This data cannot be scanned from tags | The below table details the '''additional''' information {{kodi}} scrapes into the library. This data cannot be scanned from tags. | ||
{|class="prettytable" | {|class="prettytable" | ||
|- | |- | ||
| style=" width:150px; text-align:left;" | | ! colspan="8" style=" background-color:#12b2e7; text-align:left;" | '''Album Metadata''' | ||
| style=" width:150px; text-align:left;" | | |- | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | moods | ||
| style=" width:150px; text-align:left;" | Album | | style=" width:150px; text-align:left;" | mbid's (artwork related) | ||
| style=" width:150px; text-align:left;" | musicbrainzreleasegroupid | |||
| style=" width:150px; text-align:left;" | rating | |||
| style=" width:150px; text-align:left;" | review | |||
| style=" width:150px; text-align:left;" | styles | |||
| style=" width:150px; text-align:left;" | theme | |||
| style=" width:150px; text-align:left;" | votes | |||
|- | |||
! colspan="8" style=" background-color:#12b2e7; text-align:left;" | '''Album Artwork''' | |||
|- | |- | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | back | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | discart | ||
| style=" width:150px; text-align:left;" | | | style=" width:150px; text-align:left;" | fanart | ||
| style=" width:150px; text-align:left;" | folder (thumb) | |||
| style=" width:150px; text-align:left;" | spine | |||
|} | |} | ||
== What is Overwritten == | |||
Some information that has been scanned from music file tags can be overwritten with data derived from the scraping process. This can be useful if your tags are incomplete or outdated. It allows the library (not the music file tags) to be updated with current data. | |||
To allow this to occur, '''Enable''' the following setting. Leave it '''Disabled''' if you are happy with your music file tags. | |||
:'''''See: [[Settings/Media/Music#Prefer_online_information|Prefer Online Information]]''''' | |||
The two tables in the following link detail which entries can be overwritten for artists and albums. | |||
:'''''See: [[Music#Available_nfo_Tags|Available NFO Tags]]''''' | |||
= Scrapers = | |||
A number of scrapers are available to install, most catering to specific music genres. | |||
By default {{kodi}} uses the following scrapers | |||
*Artists- '''''[[Add-on:Universal_Artist_Scraper|Universal Artist Scraper]]''''' | |||
*Albums- '''''[[Add-on:Universal_Album_Scraper|Universal Album Scraper]]''''' | |||
These two scrapers will search MusicBrainz, last.fm, allmusic.com and amazon.de for metadata and fanart.tv, last.fm and allmusic.com for artwork. | |||
They are also the only two scrapers that currently downloads '''Extended Artwork'''. | |||
: '''''See also: List of [[:Category:Artist_scraper_add-ons| Artist Scrapers]]''''' | |||
: '''''See also: List of [[:Category:Album_scraper_add-ons| Album Scrapers]]''''' | |||
== Extended Artwork == | |||
:{{main|Artwork}} | |||
New in v18 is the feature to scrape and cache extended artwork in the music (and video) library without the need for additional add-ons. This is still an experimental feature (to work out bugs). <ref>https://github.com/xbmc/xbmc/pull/13848</ref> | |||
'''Basic''' Artwork consists of: | |||
*Artists- fanart, folder | |||
*Albums- folder | |||
'''Extended''' Artwork consists of: | |||
*Artists- banner, clearart, clearlogo, extra fanart, landscape | |||
*Albums- back, discart, spine | |||
To use this feature, there are two requirements as follows: | |||
;1. The following tags are required in the '''''[[advancedsettings.xml]]''''' file and {{kodi}} restarted before scraping. | |||
<syntaxhighlight lang="xml" line='line'> | |||
<advancedsettings> | |||
<musiclibrary> | |||
<artistextraart> | |||
<arttype>banner</arttype> | |||
<arttype>clearart</arttype> | |||
<arttype>clearlogo</arttype> | |||
<arttype>landscape</arttype> | |||
<arttype>fanart1</arttype> | |||
<arttype>fanart2</arttype> | |||
<arttype>fanart3</arttype> | |||
<arttype>fanart4</arttype> | |||
</artistextraart> | |||
<albumextraart> | |||
<arttype>back</arttype> | |||
<arttype>discart</arttype> | |||
<arttype>spine</arttype> | |||
</albumextraart> | |||
</musiclibrary> | |||
</advancedsettings> | |||
</syntaxhighlight> | |||
;2. Scraper Settings | |||
The default Universal Artist Scraper and Universal Album Scraper have been updated to scrape extended artwork. These settings are disabled by default and '''need to be enabled in the scraper settings''' pages. | |||
:'''''See: [[Add-on:Universal_Artist_Scraper|Universal Artist Scraper]]'''''<br> | |||
:'''''See: [[Add-on:Universal_Album_Scraper|Universal Album Scraper]]''''' | |||
== Extra Fanart == | |||
Extra Fanart was traditionally saved in the extrafanart folder. Additional fanart images were saved to this folder for use as a slideshow by a compatible skin, usually by utilising the Skin Helper Service add-on or the Artist Slideshow add-on. The downside to this method is the skin needs to read the extra fanart directly from the extrafanart folder. This requires hard drives to wake causing delays in the GUI while waiting for the drives to become accessible. Filenames are not important as the skin slideshow simply displayed any image file in the folder. | |||
v18 introduces caching of extra fanart, just like any other artwork in the library, and is also considered experimental. The advantages are quicker loading times and fewer wakings of hard disks. It is more difficult for skinners to implement this method. | |||
Only a few skins are currently supporting this method, but more skins will implement this in the future. | |||
There are three requirements to using this method... | |||
;1. Compatible Skin | |||
:Check with the skinner if this method is used by the skin. | |||
;2. advancedsettings.xml | |||
:Tags are required in the advancedsettings.xml file as shown in the previous section. | |||
;3. Saving Extra Fanart | |||
:The extra fanart must be saved alongside the other artwork (as shown in the image) with the following requirements: | |||
:*'''''fanart#''''' is Extra Fanart. As many or as few can be added, but there must be a corresponding whitelist entry in the advancedsettings.xml file as shown above. | |||
:*Do not zero pad the digits, ie use 1 not 01; use 12 not 012 | |||
:*The Music Library does not support the use of the Extrafanart folder | |||
:*The Universal Artist Scraper does not download extra fanart. The extra fanart must be manually sourced and added to the Artist folder | |||
<section begin="ScrapeArtists" /><gallery mode="packed" widths="500px" heights="283px"> | |||
File:Artwork-FolderView01.jpg|Artist folder containing correctly named artwork | |||
</gallery> | |||
= Performing the Scrape = | = Performing the Scrape = | ||
The following two sections will guide you through the scrape process. Be aware that | The following two sections will guide you through the scrape process. Be aware that scraping Artist and Albums are two separate processes. | ||
== Artists == | == Artists == | ||
<section begin="ScrapeArtists" /><gallery widths=500px heights= | <section begin="ScrapeArtists" /><gallery mode="packed" widths="500px" heights="283px"> | ||
File:Estuary_home_music_files.png|Image 1 | File:Estuary_home_music_files.png|Image 1 | ||
File:Music-CategoryList.jpg|Image 2 | File:Music-CategoryList.jpg|Image 2 | ||
| Line 94: | Line 201: | ||
#Select '''Artists''' from the category list (Image 2) | #Select '''Artists''' from the category list (Image 2) | ||
#Highlight any Artist (Image 3) | #Highlight any Artist (Image 3) | ||
#Call up the Context Menu for the selected Artist (Image 3) | #Call up the '''[[Basic_controls#Context_Menu|Context Menu]]''' for the selected Artist (Image 3) | ||
#Select '''Query info for all artists''' (Image 3)<section end="ScrapeArtists" /> | #Select '''Query info for all artists''' (Image 3)<section end="ScrapeArtists" /> | ||
| Line 103: | Line 210: | ||
== Albums == | == Albums == | ||
<section begin="ScrapeAlbums" /><gallery widths=500px heights= | <section begin="ScrapeAlbums" /><gallery mode="packed" widths="500px" heights="283px"> | ||
File:Estuary_home_music_files.png|Image 1 | File:Estuary_home_music_files.png|Image 1 | ||
File:Music-CategoryList.jpg|Image 2 | File:Music-CategoryList.jpg|Image 2 | ||
| Line 114: | Line 221: | ||
#Select '''Albums''' from the category list (Image 2) | #Select '''Albums''' from the category list (Image 2) | ||
#Highlight any Album (Image 3) | #Highlight any Album (Image 3) | ||
#Call up the Context Menu for the selected Album (Image 3) | #Call up the '''[[Basic_controls#Context_Menu|Context Menu]]''' for the selected Album (Image 3) | ||
#Select '''Query info for all albums''' (Image 3) <section end="ScrapeAlbums" /> | #Select '''Query info for all albums''' (Image 3) <section end="ScrapeAlbums" /> | ||
| Line 120: | Line 227: | ||
Once complete, the scrape should be run a second time to ensure "busy" responses were not received from the scraper site due to overloaded servers. | Once complete, the scrape should be run a second time to ensure "busy" responses were not received from the scraper site due to overloaded servers. | ||
= Unscraped Items = | |||
Unfortunately there are numerous<ref>https://en.wikipedia.org/wiki/List_of_online_music_databases</ref> <ref>https://yadg.cc/available-scrapers</ref> online music databases that contain artist and album information. Not all of them allow API access, and no one site is complete as every user has their preference of which site to update. Simply put, there is no IMDB or TheMovieDB equivelant for music, though ''discogs.com'' seems to be the largest of all the online databases. | |||
When browsing your library, it will become apparent that not all Artists or Albums had additional information scraped. When a scrape fails due to no data available your options are | |||
#Contribute back to the free sites used by the {{kodi}} scrapers and update missing and incorrect entries (preferred option) | |||
#Create [[NFO files]] which contain the additional information. | |||
If using the NFO files option, a quick guide is... | |||
#Create your [[Artist information folder]] without subfolders somewhere outside of your Music Source(s). | |||
#Set the [[Artist information folder]] in the '''''[[Settings/Media/Music#Artist_information_folder|Music Settings]]''''' page | |||
#Use the export option '''''[[Import-export_library/Music#Artist_folders_only|Artist Folders only]]''''' to create the artist subfolders | |||
#Locate artwork | |||
#*Artists- save it in the Artist's folder in the [[Artist information folder]], using the naming scheme displayed above | |||
#*Albums- save it in the Album folder containing the music files | |||
#Create [[NFO files]] and enter the additional data to be added to the library and | |||
#*Artists- save it in the Artist's folder in the [[Artist information folder]], named '''artist.nfo''' | |||
#*Albums- save it in the Album folder containing the music files and name it '''album.nfo''' | |||
#*See '''''[[NFO_files/Music|Music NFO files]]''''' for sample Artist and Album nfo files. | |||
#'''Refresh''' the new information into the library | |||
#*Artists... '''''[[Update_Music_Library#Refresh_Artist|Artist Refresh]]''''' | |||
#*Albums... '''''[[Update_Music_Library#Refresh_Album|Album Refresh]]''''' | |||
| Line 130: | Line 262: | ||
Display of scraped information using alternate skins: | Display of scraped information using alternate skins: | ||
<gallery widths=500px heights= | <gallery mode="packed" widths="500px" heights="283px"> | ||
File:Music-AdditionalInfo03.jpg|Transparency! | File:Music-AdditionalInfo03.jpg|Transparency! | ||
File:Music-AdditionalInfo01.jpg|Rapier | File:Music-AdditionalInfo01.jpg|Rapier | ||
File:Music-AdditionalInfo02.jpg|Aeon Nox | File:Music-AdditionalInfo02.jpg|Aeon Nox | ||
File:Artwork-MusicBanner01.jpg|Aeon MQ7 mode | |||
File:Artwork-TS-clearart-AeonNox5modmaybe.jpg | |||
</gallery> | </gallery> | ||
{{-}} | {{-}} | ||
---- | |||
<center>{{red|'''The remainder of this page deals with special use cases or provides information for technical interest and reference only. It can be safely disregarded if these do not apply to you'''}}</center> | |||
---- | |||
<div style="{{linear-gradient|left|#f5d3ff, #12b2e7}}">{{next|[[Update_Music_Library|Update Music Library]]}} </div> | |||
= Technical Details = | |||
'''Scraping of additional artist and album information does not happen when you run a library update (including when first adding a source) unless "Fetch additional info on update" is enabled.''' Currently this defaults to '''disabled'''. It is strongly recommended to keep this disabled for several reasons: | |||
*It allows you to perform the initial tag scan quickly. In v17 and below, when ''Fetch additional info on update'' is ''enabled'', the two steps happen immediately each album and artist is added. This slows down populating the library. It is a background task, but still gives the impression that it is taking a considerable time to populate the library. In reality it is slowed down by the online scraping, and not the local tag scanning. This will be changed in v18 where {{kodi}} will perform the initial tag scan then, once complete, will commence the online scrape. | |||
*The strategy of immediately scraping each album and artist as it is added can also have unwanted consequences. A common example involves compilation albums. Say for example you have both ''Fetch additional info on update'' and ''Show song and album artists'' as ''enabled'', and a folder called "Compilations" containing all your Various Artist compliation albums. As the processing takes place in alphabetical order, this folder gets processed ''before'' the albums of artists in folders beginning with a letter later in the alphabet. The additional information for the song artists from these compilation albums gets added to the library and scraped before the other albums by that artist had been scanned, and so any artist.nfo file is never found and applied. | |||
*Bad tagging makes a messy library and then the online scrape compounds errors and makes the library difficult to unscramble. It is far better for the user to perform the initial scan, find and fix the bad tags, then perform the on-line scrape knowing there will be no further errors. | |||
*Scraping online also often leaves many gaps on first pass, then the user has to manually ''query for all'' anyway, often several times, to fill these gaps. This was because lack of correct throttling, and general server overload has meant that online scraping often failed (seen in the log as ''503 server errors''). This is expected to be fixed for v18. | |||
= References = | |||
<references /> | |||
| Line 142: | Line 299: | ||
{{Top}} | {{Top}} | ||
<div style="{{linear-gradient|left|#f5d3ff, #12b2e7}}">{{next|[[ | <div style="{{linear-gradient|left|#f5d3ff, #12b2e7}}">{{next|[[Update_Music_Library|Update Music Library]]}} </div> | ||
{{updated| | {{updated|18}} | ||
[[Category:FAQ]] | [[Category:FAQ]] | ||
[[Category:Index]] | [[Category:Index]] | ||
Revision as of 03:16, 16 April 2019
| Steps to create your Music Library |
|---|
 |
| 1. Guide Main Page |
| 2. Music Settings |
| 3. Music File Tagging |
| 4. Scanning Music Into Library |
| 5. Artist information folder |
| 6. Scraping Additional Music data
|
| 7. Update Music Library |
8. NFO Files
|
9. Artwork
|
10. Import-export library
|
| 11. Backup & Recover |
 |
Introduction
Music Scraping downloads additional information about the Artists and Albums in your library, as well as downloading any missing artwork. This step is optional, but if you choose to scrape, it must be performed after your music is Scanned into the library.
The source of information for the scrape can be either:
- An online source using one of the Kodi Scrapers
- Local information from either NFO files or data in a Single File export.
For this guide, it is assumed this is your first setup, so you will have no local files. The scraped data is being retrieved from an online source using the scrapers.
v18 introduces a number of changes and improvements to scraping. The most prominent being the Artist information folder. Also new is the ability for Kodi and the scrapers to download and cache Extended Artwork. These are covered below.
What is Scraped
If the information and artwork is available at the online site used by the active scrapers, the scraping process will download the additional data and artwork into your existing library.
Artists
The below table details the additional information Kodi scrapes into the library. This data cannot be scanned from tags.
| Artist Metadata | |||||||
|---|---|---|---|---|---|---|---|
| biography | birthday date and place | date and place died | disambiuation | discography | gender | genres | instruments |
| mbid's | moods | SortName | type | styles | years active | (band) formed | (band) disbanded |
| Artist Artwork | |||||||
| banner | clearart | clearlogo | fanart | fanart# (extrafanart) | folder (thumb) | landscape | |
Albums
The below table details the additional information Kodi scrapes into the library. This data cannot be scanned from tags.
| Album Metadata | |||||||
|---|---|---|---|---|---|---|---|
| moods | mbid's (artwork related) | musicbrainzreleasegroupid | rating | review | styles | theme | votes |
| Album Artwork | |||||||
| back | discart | fanart | folder (thumb) | spine | |||
What is Overwritten
Some information that has been scanned from music file tags can be overwritten with data derived from the scraping process. This can be useful if your tags are incomplete or outdated. It allows the library (not the music file tags) to be updated with current data.
To allow this to occur, Enable the following setting. Leave it Disabled if you are happy with your music file tags.
The two tables in the following link detail which entries can be overwritten for artists and albums.
- See: Available NFO Tags
Scrapers
A number of scrapers are available to install, most catering to specific music genres.
By default Kodi uses the following scrapers
- Artists- Universal Artist Scraper
- Albums- Universal Album Scraper
These two scrapers will search MusicBrainz, last.fm, allmusic.com and amazon.de for metadata and fanart.tv, last.fm and allmusic.com for artwork.
They are also the only two scrapers that currently downloads Extended Artwork.
- See also: List of Artist Scrapers
- See also: List of Album Scrapers
Extended Artwork
- Main page: Artwork
New in v18 is the feature to scrape and cache extended artwork in the music (and video) library without the need for additional add-ons. This is still an experimental feature (to work out bugs). [1]
Basic Artwork consists of:
- Artists- fanart, folder
- Albums- folder
Extended Artwork consists of:
- Artists- banner, clearart, clearlogo, extra fanart, landscape
- Albums- back, discart, spine
To use this feature, there are two requirements as follows:
- 1. The following tags are required in the advancedsettings.xml file and Kodi restarted before scraping.
<advancedsettings> <musiclibrary> <artistextraart> <arttype>banner</arttype> <arttype>clearart</arttype> <arttype>clearlogo</arttype> <arttype>landscape</arttype> <arttype>fanart1</arttype> <arttype>fanart2</arttype> <arttype>fanart3</arttype> <arttype>fanart4</arttype> </artistextraart> <albumextraart> <arttype>back</arttype> <arttype>discart</arttype> <arttype>spine</arttype> </albumextraart> </musiclibrary> </advancedsettings>
- 2. Scraper Settings
The default Universal Artist Scraper and Universal Album Scraper have been updated to scrape extended artwork. These settings are disabled by default and need to be enabled in the scraper settings pages.
Extra Fanart
Extra Fanart was traditionally saved in the extrafanart folder. Additional fanart images were saved to this folder for use as a slideshow by a compatible skin, usually by utilising the Skin Helper Service add-on or the Artist Slideshow add-on. The downside to this method is the skin needs to read the extra fanart directly from the extrafanart folder. This requires hard drives to wake causing delays in the GUI while waiting for the drives to become accessible. Filenames are not important as the skin slideshow simply displayed any image file in the folder.
v18 introduces caching of extra fanart, just like any other artwork in the library, and is also considered experimental. The advantages are quicker loading times and fewer wakings of hard disks. It is more difficult for skinners to implement this method.
Only a few skins are currently supporting this method, but more skins will implement this in the future.
There are three requirements to using this method...
- 1. Compatible Skin
- Check with the skinner if this method is used by the skin.
- 2. advancedsettings.xml
- Tags are required in the advancedsettings.xml file as shown in the previous section.
- 3. Saving Extra Fanart
- The extra fanart must be saved alongside the other artwork (as shown in the image) with the following requirements:
- fanart# is Extra Fanart. As many or as few can be added, but there must be a corresponding whitelist entry in the advancedsettings.xml file as shown above.
- Do not zero pad the digits, ie use 1 not 01; use 12 not 012
- The Music Library does not support the use of the Extrafanart folder
- The Universal Artist Scraper does not download extra fanart. The extra fanart must be manually sourced and added to the Artist folder
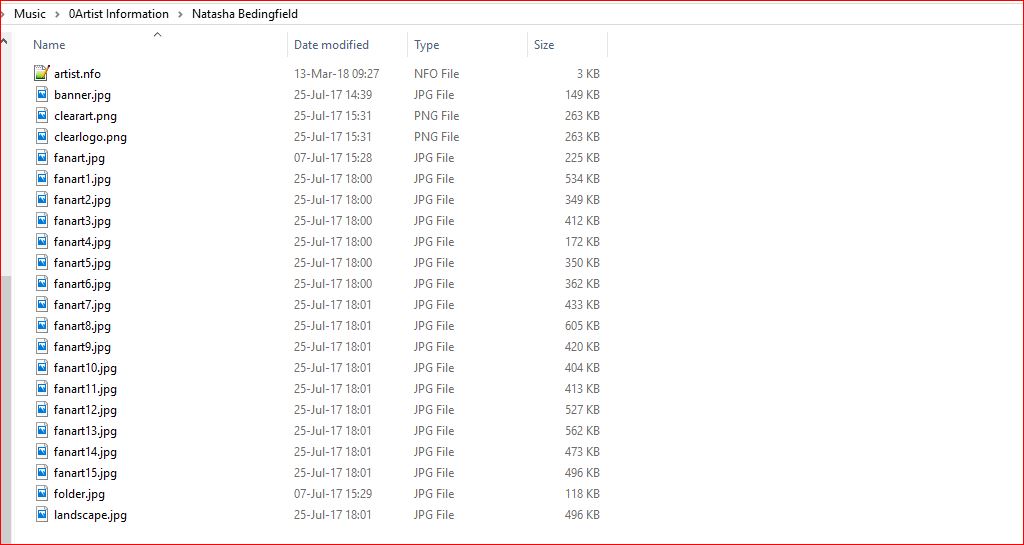
Artist folder containing correctly named artwork

Performing the Scrape
The following two sections will guide you through the scrape process. Be aware that scraping Artist and Albums are two separate processes.
Artists
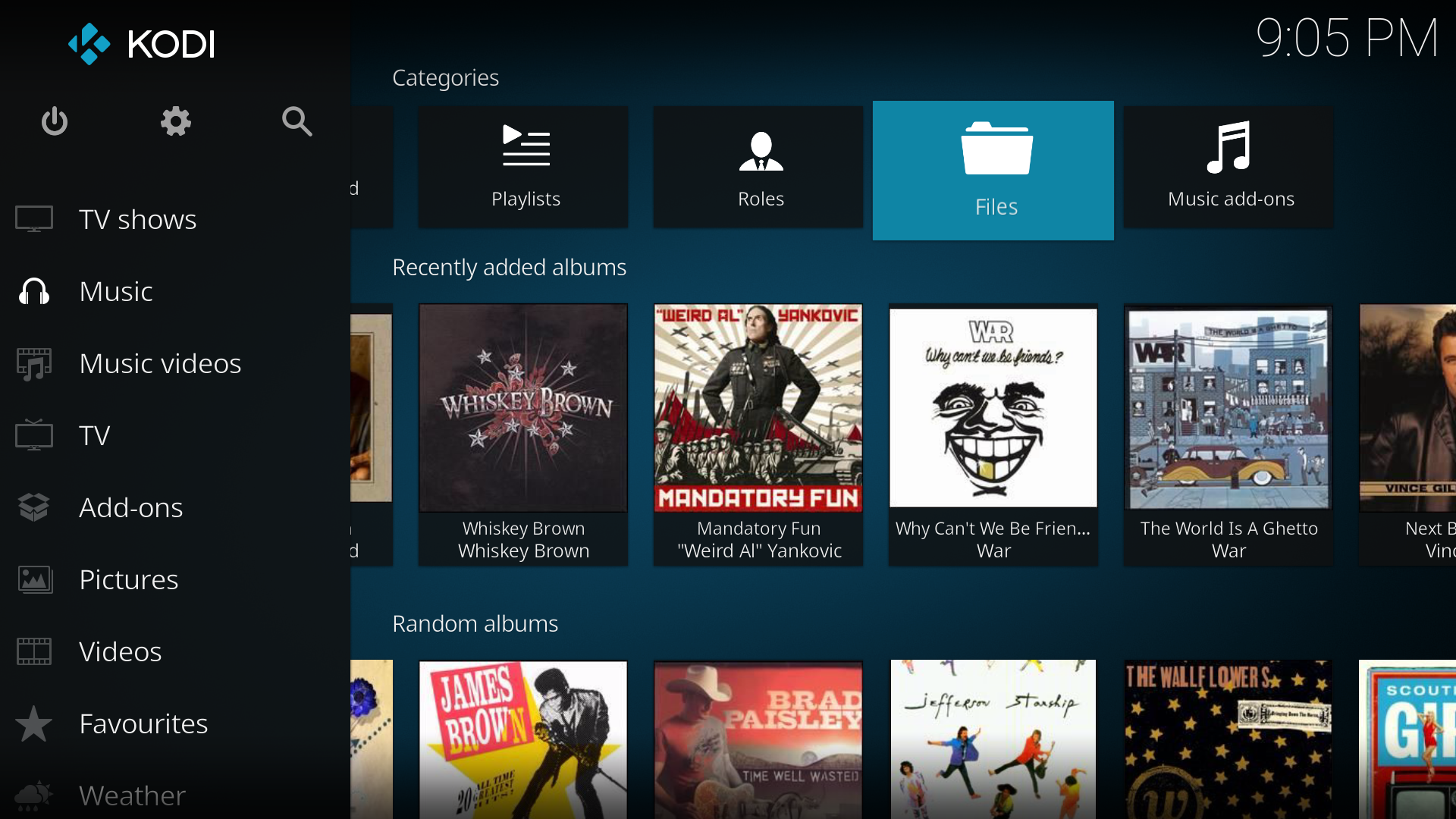
Image 1
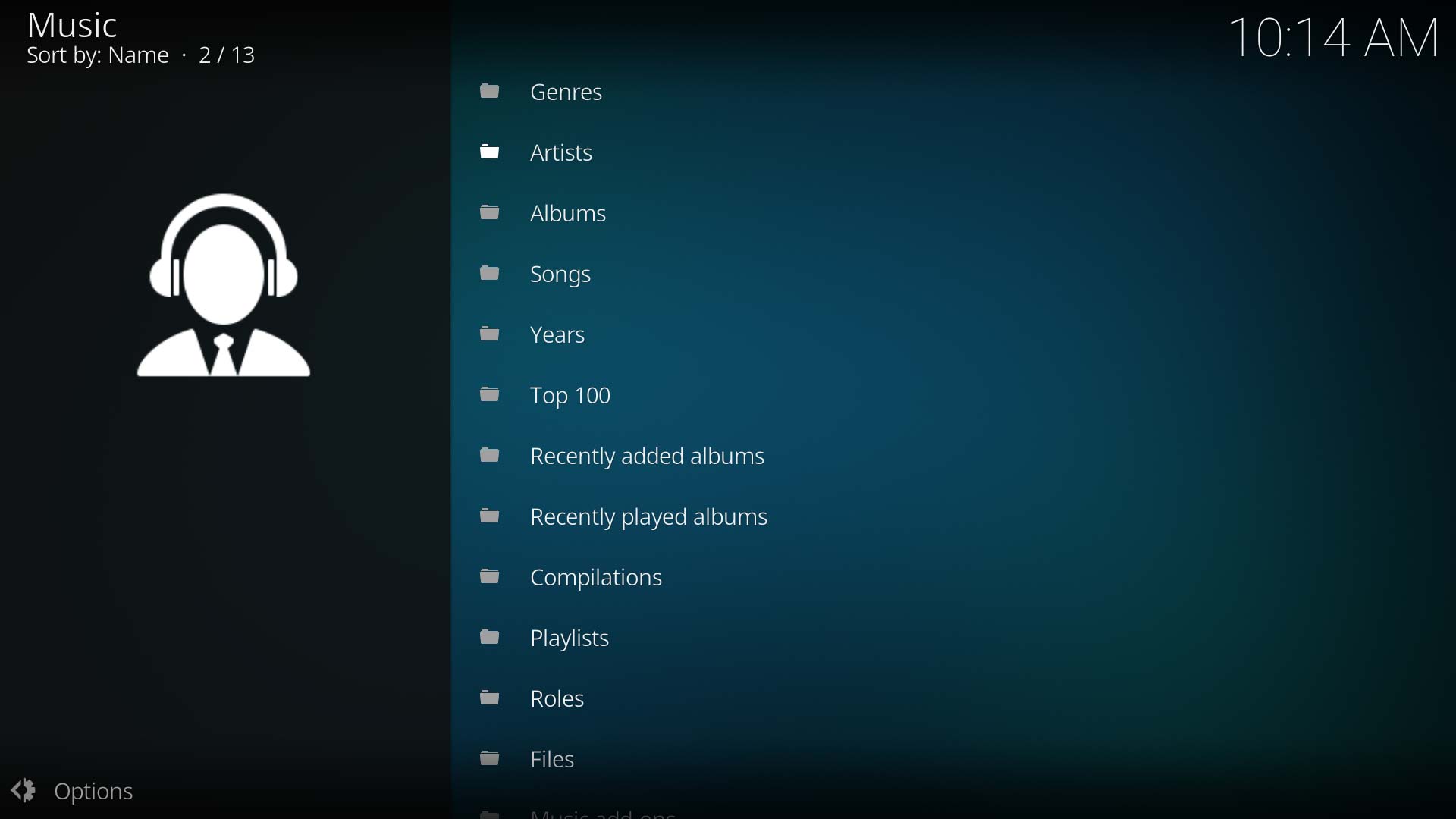
Image 2
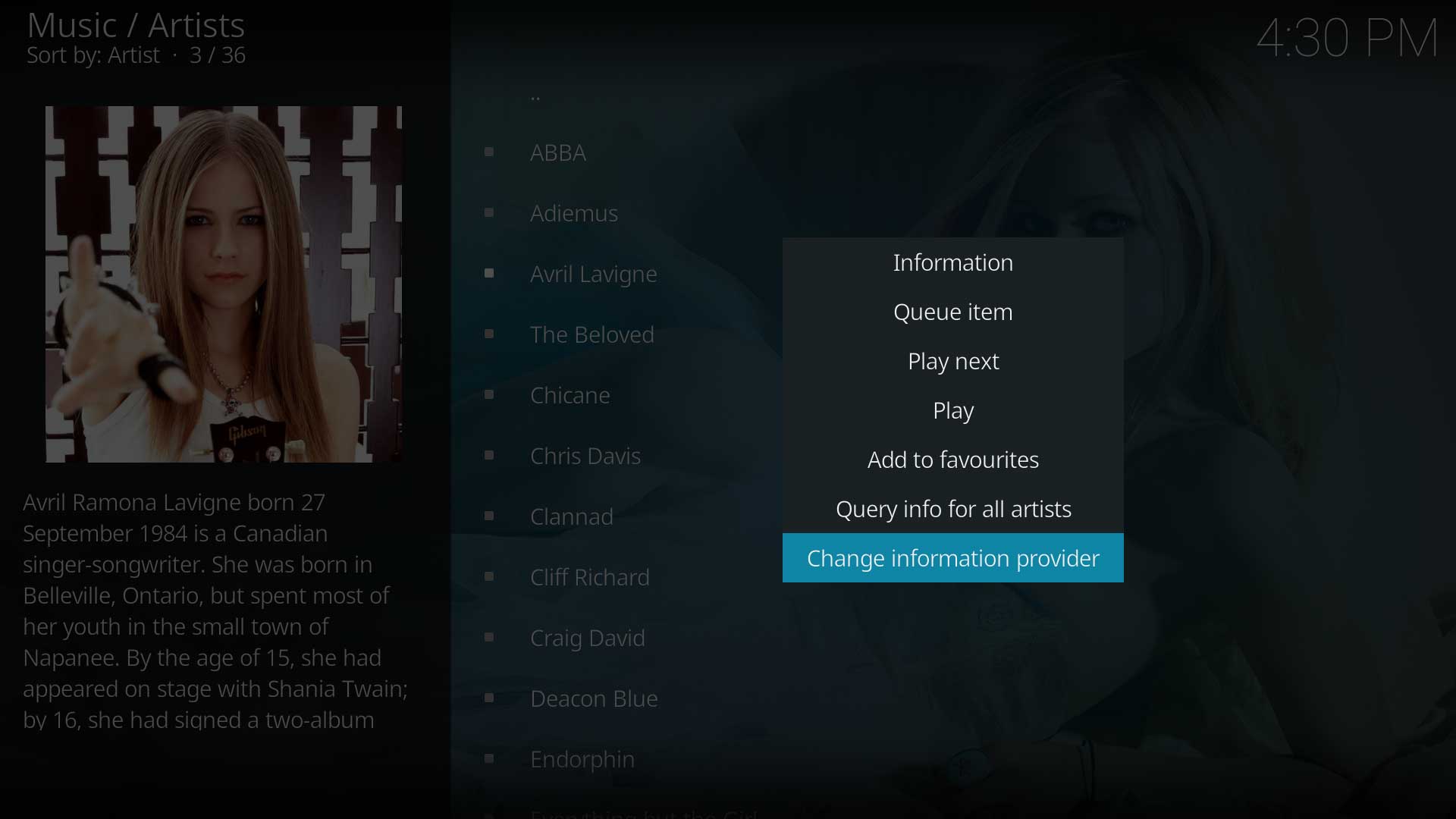
Image 3



To scrape additional information for Artists, follow these steps:
- Select Music from the main menu (Image 1)
- Select Artists from the category list (Image 2)
- Highlight any Artist (Image 3)
- Call up the Context Menu for the selected Artist (Image 3)
- Select Query info for all artists (Image 3)
Depending upon the size of your library, this process could take many hours. As an example, a library of around 900 artists required over three hours to complete the scrape. This is dependent on your internet connection and the load on the servers hosting the scraper database. It is best to perform the scrape overnight when Kodi is not in use.
Once complete, it should be run a second time to ensure "busy" responses were not received from the scraper site due to overloaded servers.
Albums
Image 1
Image 2
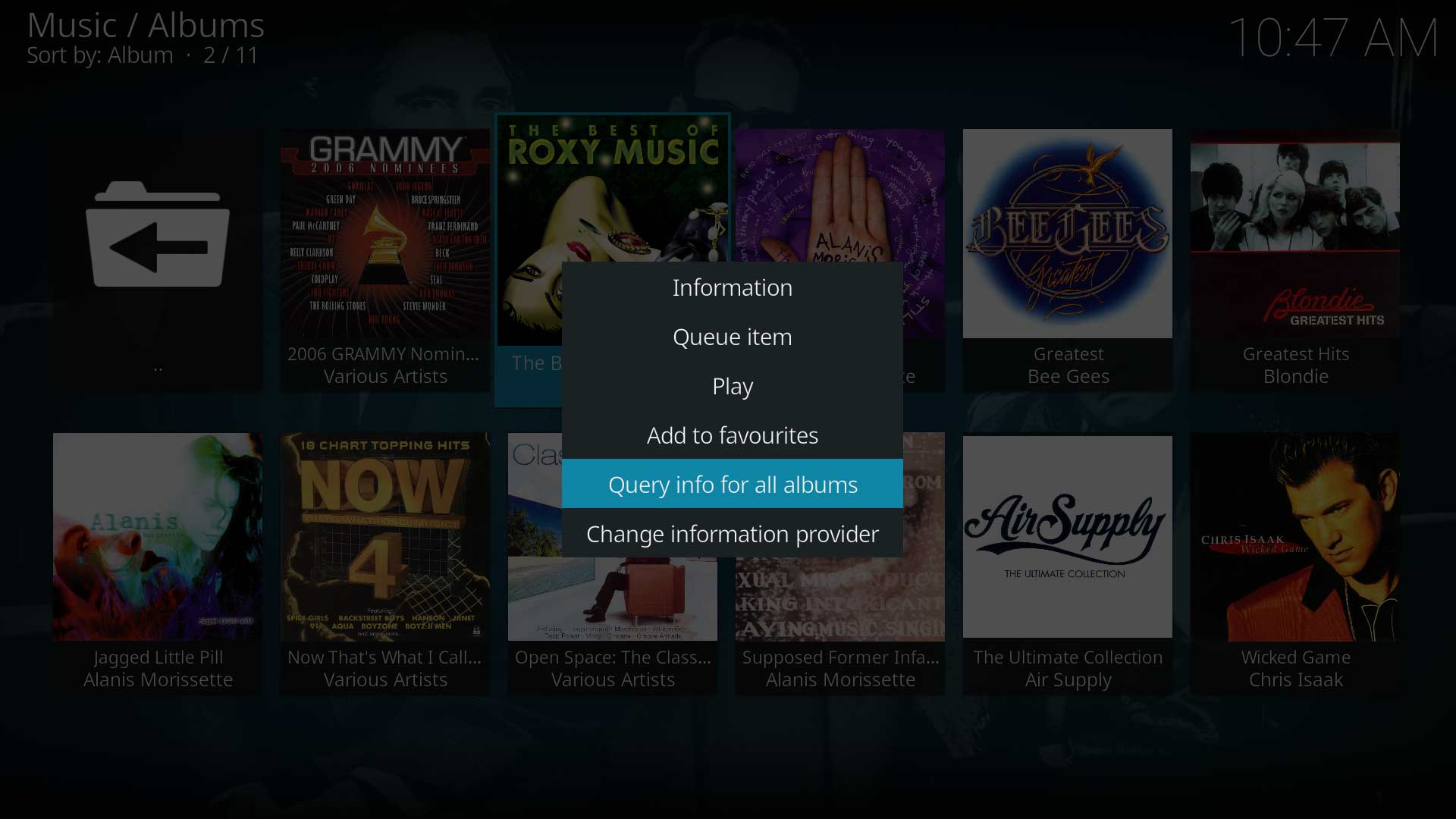
Image 3

To scrape additional information for Albums, follow these steps:
- Select Music from the main menu (Image 1)
- Select Albums from the category list (Image 2)
- Highlight any Album (Image 3)
- Call up the Context Menu for the selected Album (Image 3)
- Select Query info for all albums (Image 3)
Depending upon the size of your library, this process could take many hours. As an example, a library of around 300 albums required almost two hours to complete the scrape. This is dependent on your internet connection and the load on the servers hosting the scraper database. It is best to perform the scrape overnight when Kodi is not in use.
Once complete, the scrape should be run a second time to ensure "busy" responses were not received from the scraper site due to overloaded servers.
Unscraped Items
Unfortunately there are numerous[2] [3] online music databases that contain artist and album information. Not all of them allow API access, and no one site is complete as every user has their preference of which site to update. Simply put, there is no IMDB or TheMovieDB equivelant for music, though discogs.com seems to be the largest of all the online databases.
When browsing your library, it will become apparent that not all Artists or Albums had additional information scraped. When a scrape fails due to no data available your options are
- Contribute back to the free sites used by the Kodi scrapers and update missing and incorrect entries (preferred option)
- Create NFO files which contain the additional information.
If using the NFO files option, a quick guide is...
- Create your Artist information folder without subfolders somewhere outside of your Music Source(s).
- Set the Artist information folder in the Music Settings page
- Use the export option Artist Folders only to create the artist subfolders
- Locate artwork
- Artists- save it in the Artist's folder in the Artist information folder, using the naming scheme displayed above
- Albums- save it in the Album folder containing the music files
- Create NFO files and enter the additional data to be added to the library and
- Artists- save it in the Artist's folder in the Artist information folder, named artist.nfo
- Albums- save it in the Album folder containing the music files and name it album.nfo
- See Music NFO files for sample Artist and Album nfo files.
- Refresh the new information into the library
- Artists... Artist Refresh
- Albums... Album Refresh
End of Setup
Congratulations! You have reached the end of the second module of the Setup Guide. You should now have a fully functioning Music library full of information and artwork.
The following steps in the guide will help you tweak and modify your library. There is no requirement for you to read on at this stage. Become comfortable with your new library. When you feel there is need for a change, come back to this guide and continue with the remaining modules. We do recommend you take care to backup your library.
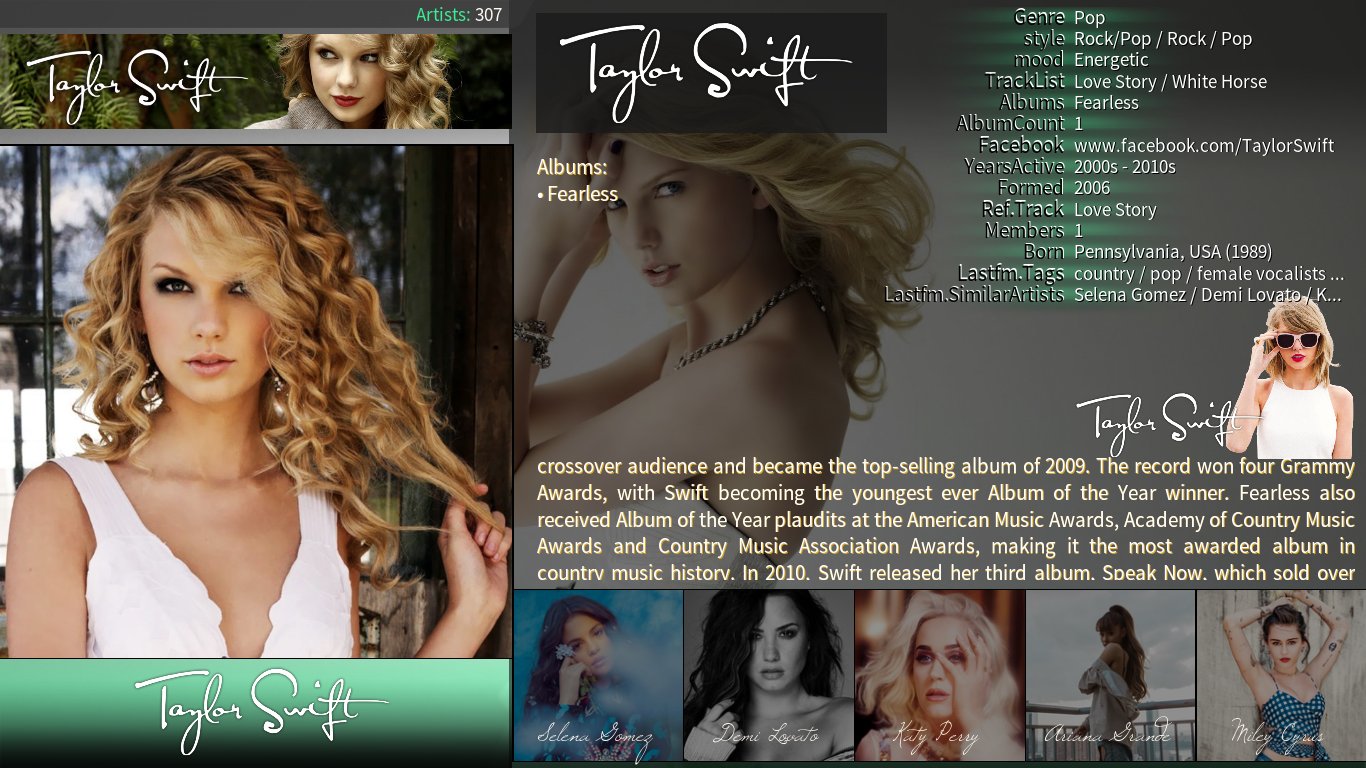
Display of scraped information using alternate skins:
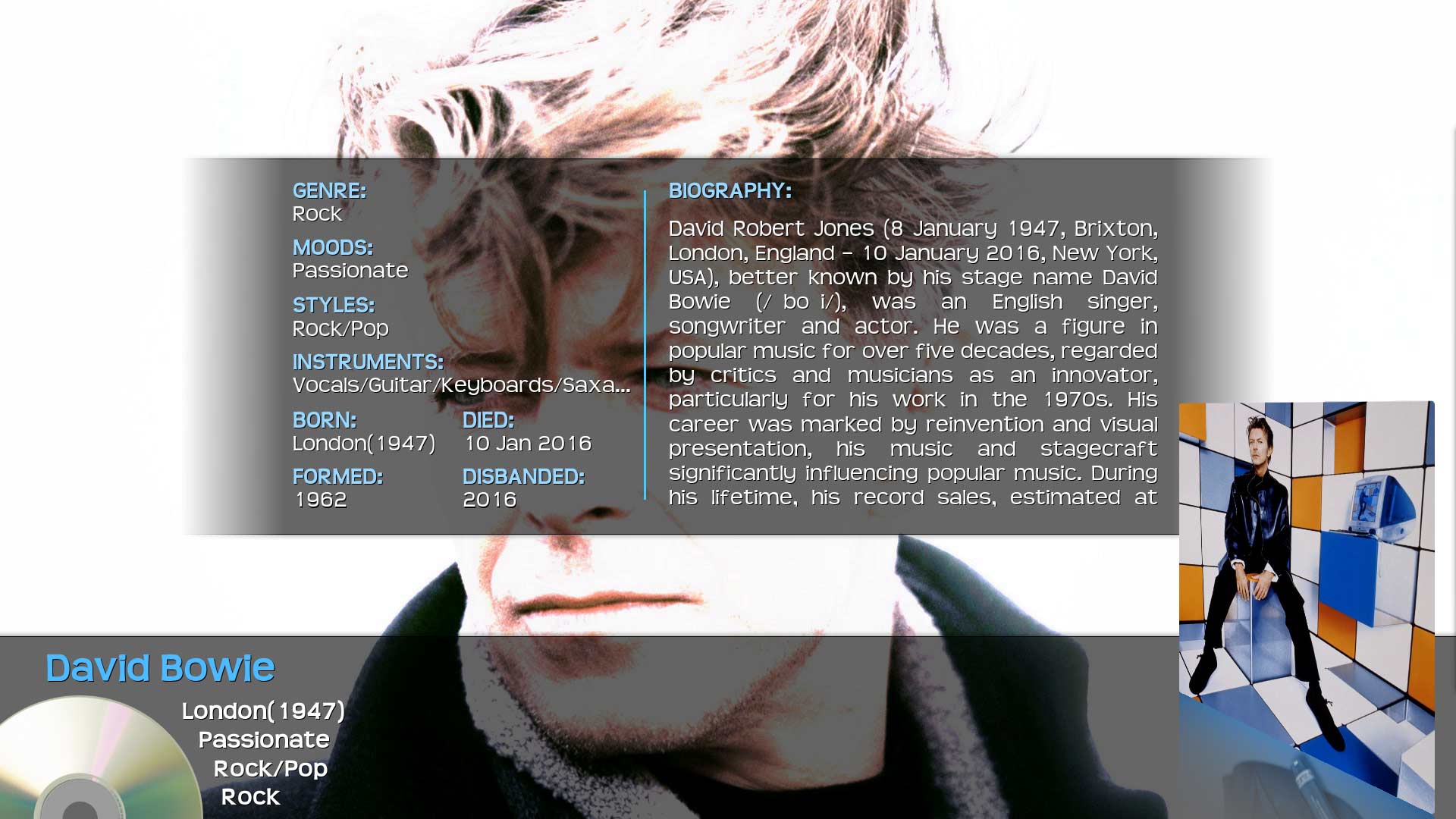
Transparency!
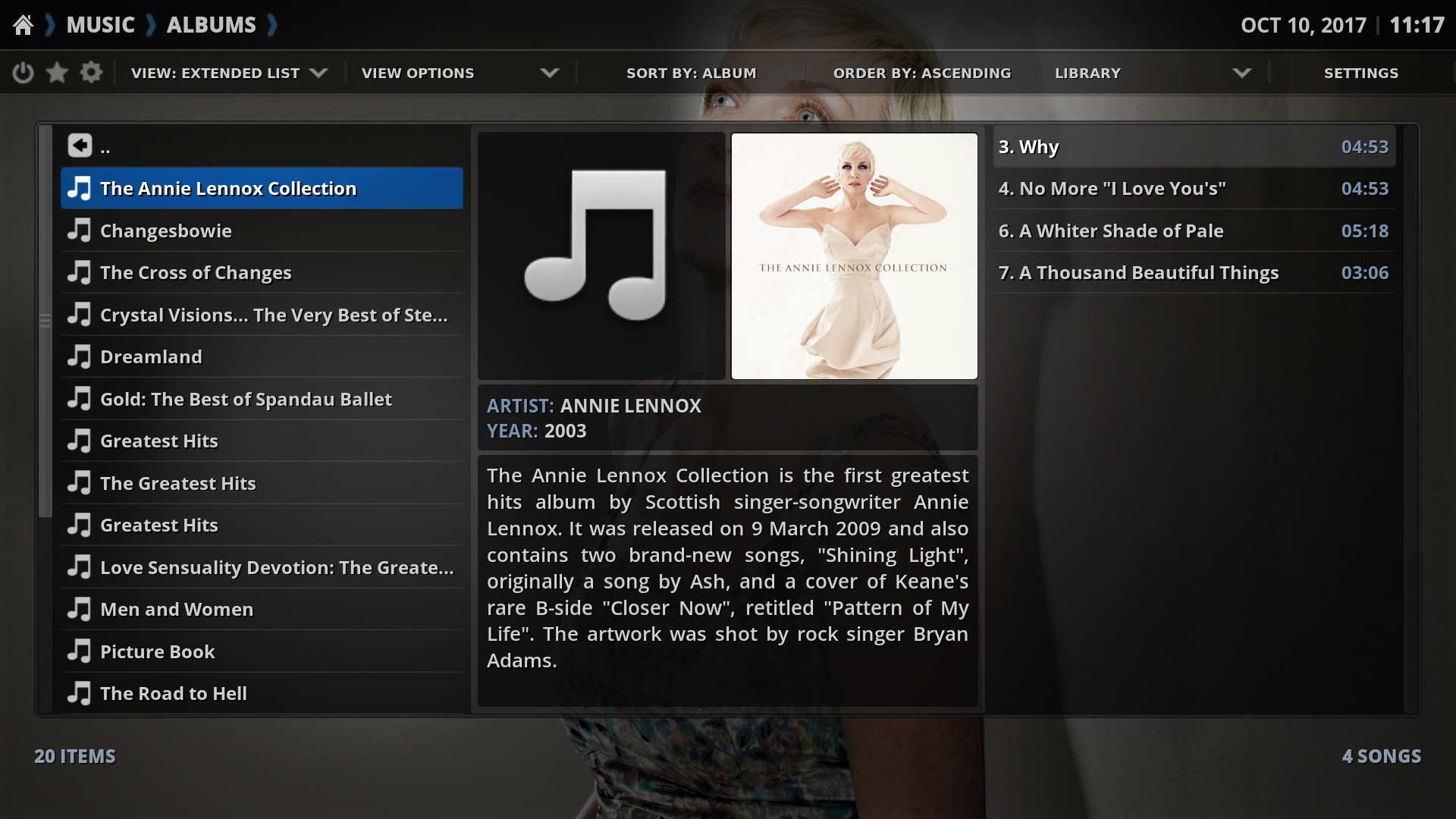
Rapier
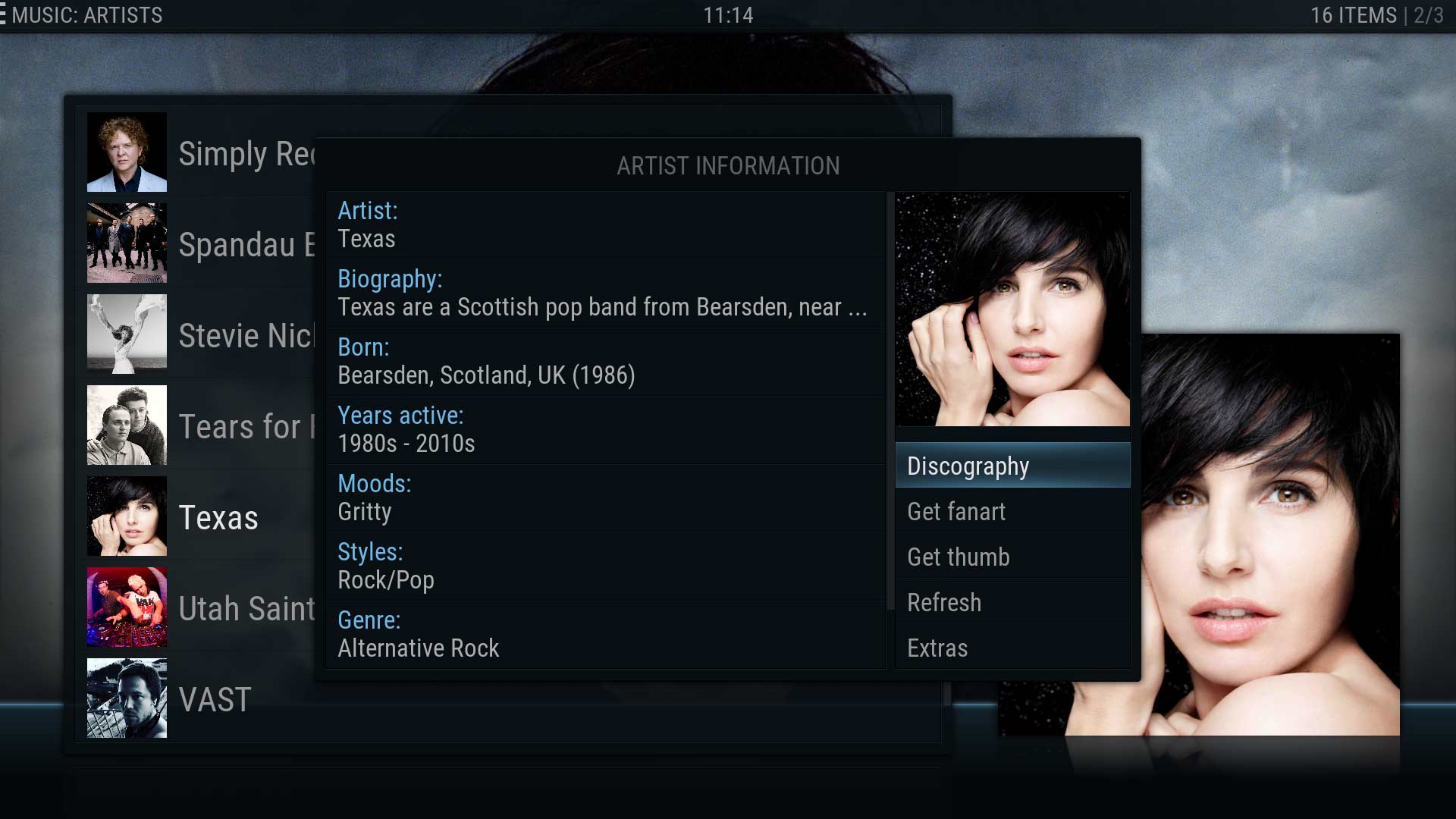
Aeon Nox

Aeon MQ7 mode





| Next step: | Update Music Library |
Technical Details
Scraping of additional artist and album information does not happen when you run a library update (including when first adding a source) unless "Fetch additional info on update" is enabled. Currently this defaults to disabled. It is strongly recommended to keep this disabled for several reasons:
- It allows you to perform the initial tag scan quickly. In v17 and below, when Fetch additional info on update is enabled, the two steps happen immediately each album and artist is added. This slows down populating the library. It is a background task, but still gives the impression that it is taking a considerable time to populate the library. In reality it is slowed down by the online scraping, and not the local tag scanning. This will be changed in v18 where Kodi will perform the initial tag scan then, once complete, will commence the online scrape.
- The strategy of immediately scraping each album and artist as it is added can also have unwanted consequences. A common example involves compilation albums. Say for example you have both Fetch additional info on update and Show song and album artists as enabled, and a folder called "Compilations" containing all your Various Artist compliation albums. As the processing takes place in alphabetical order, this folder gets processed before the albums of artists in folders beginning with a letter later in the alphabet. The additional information for the song artists from these compilation albums gets added to the library and scraped before the other albums by that artist had been scanned, and so any artist.nfo file is never found and applied.
- Bad tagging makes a messy library and then the online scrape compounds errors and makes the library difficult to unscramble. It is far better for the user to perform the initial scan, find and fix the bad tags, then perform the on-line scrape knowing there will be no further errors.
- Scraping online also often leaves many gaps on first pass, then the user has to manually query for all anyway, often several times, to fill these gaps. This was because lack of correct throttling, and general server overload has meant that online scraping often failed (seen in the log as 503 server errors). This is expected to be fixed for v18.
References
| Return to top |
|---|
| Next step: | Update Music Library |